

Die Pivot-Tabelle ist für die Datenanalyse mit Excel ein etabliertes Feature. Und nun gibt es seit Excel 2010 Power Pivot. Eine leistungsstärkere Pivot-Tabelle also? Nein, Power Pivot ist ein Feature, dass es Excel-Anwendern ermöglicht Millionen Datensätze verschiedener Datenquellen zu einem Datenmodell zusammenzuführen und diese zu analysieren! Power Pivot hat eigentlich nichts mit der Pivot-Tabelle zu tun. Es ist ein Tool zur Integration und Analyse von großen Datenmengen aus verschiedenen Datenquellen.
Technisch gesehen ist Power Pivot keine Tabellenkalkulation, sondern die Oberfläche eines SQL-Servers (Microsoft Datenbank) die als lokale OLAP-Datenbank erzeugt wird. Power Pivot ist das Ergebnis einer Integration der Microsoft SQL Server Analysis Service (SSAS) durch ein Projekt-Team in Excel.
Die SQL Server Analysis Services ermöglichen das Online Analytical Processing (OLAP). Dabei werden Daten aus relationalen Datentabellen in mehrdimensionales Datenmodell überführt wird. Microsoft hat so die OLAP-Fähigkeiten in Excel integriert. Power Pivot-Modelle sind nichts anders als lokale Cubes, die durch eine Pivot-Tabelle zu einem BI-Tool werden und als Dashboard verwendet werden können. Die Ausgabe der Datenanalyse mit Power Pivot ist immer eine Pivot-Tabelle. Wichtige Berechnungen zu Datenanalyse werden mit sogenannten Measures direkt im Datenmodell vorgenommen unter Anwendung von DAX-Funktionen.
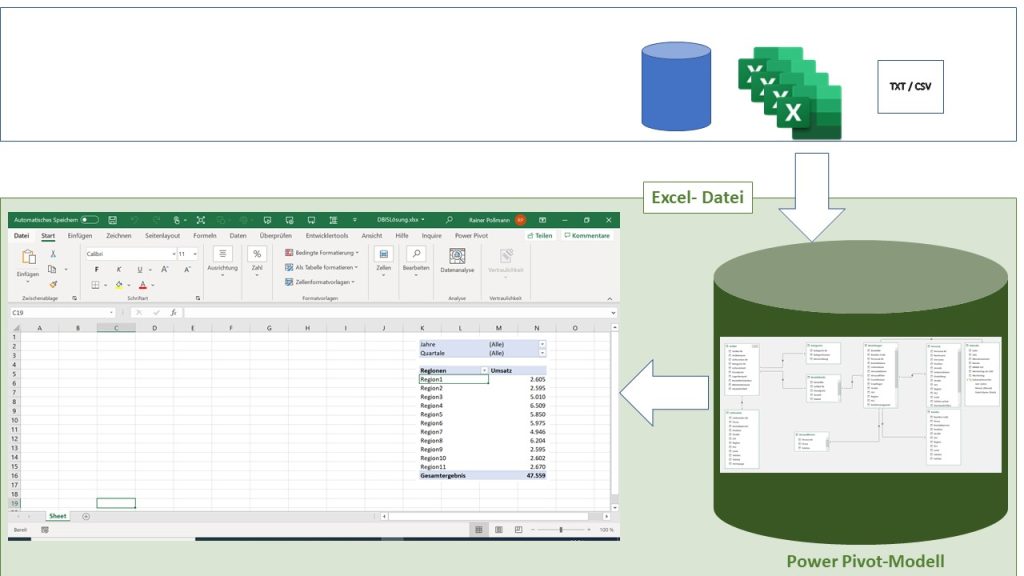
Was ist OLAP?
Die OLAP zugrunde liegende Struktur ist ein OLAP-Würfel (englisch cube), der aus der relationalen Datenbank erstellt wird. OLAP bedeutet viele Dimensionen in der Analyse zu haben . Dimensionen können zum Beispiel Kunden, Regionen, Zeit sein, aber auch Cluster, die durch Entscheidungsbäume entstanden sind. Durch diese Multidimensionalität sollen relevante betriebswirtschaftliche Kennzahlen (bspw. Umsatz- oder Kostengrößen) anhand unterschiedlicher Dimensionen mehrdimensional betrachtet und bewertet werden können. Auf Cubes basierende Data Warehouses (z.B. SAP BW) sind im Controlling eine wichtige Voraussetzung für ein Business Intelligence.
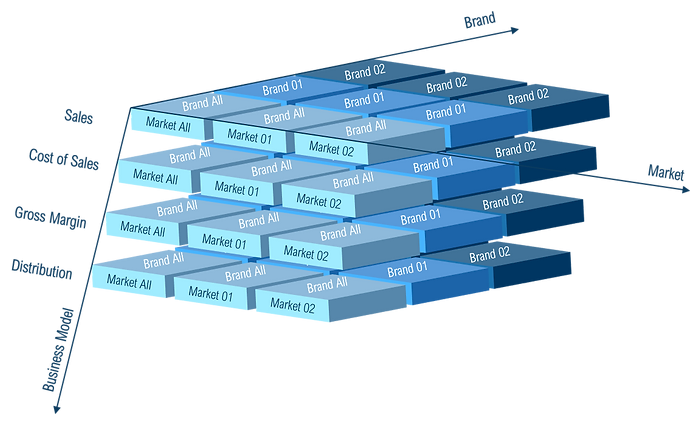
Was ist ein Power Pivot-Datenmodell?
Das Herzstück von Power Pivot ist das sogenannte Datenmodell. Das Datenmodell entsteht, wenn man innerhalb von Power Pivot
- aus verschiedenen Datenquellen Tabellen importiert,
- diese verbindet (=Beziehungen = JOINS) und Hierarchien aufbaut.
- Außerdem können berechnete Spalten und Measures (=berechnete Felder) für Analysen erstellt werden.
Mehr zum Datenmodell können Sie hier nachlesen.
Datenquellen
Im Gegensatz zu Power Query kann Power Pivot Daten nicht transformieren. Die als Datenquellen genutzten Excel- und Text-Dateien müssen eine im Sinne einer Datentabelle perfekte Struktur aufweisen (Spaltenüberschriften, Spalten und Zeilen als geschlossener Datenbereich). Bei den übrigen Datenquellen (Relationale Datenbanken, OLAP-Cubes, Data Feeds. ODC) ist das systembedingt gegeben.
Beziehungen
Bei den in das Modell eingeladenen Tabellen müssen wichtige Unterscheidungen getroffen werden:
- Es gibt Tabellen mit Bewegungsdaten, die sich in der Datenquelle sekündlich ändern können und mit jeder Aktualisierung des Datenmodells diese Änderungen auch in Power Pivot anzeigen. Tabellen mit Bewegungsdaten zeichne sich durch einen optimierten Aufbau aus, d.h. sie enthalten z.B. Artikelnummern anstelle der Artikelnamen.
- Andere Tabellen enthalten die Stammdaten, die sich in der Regel selten verändern. Durch die Beziehungen können die die Bewegungsdaten konkretisiert werden. Für eine Auswertung erscheint dann der besser verständliche Artikelname. Für diesen Vorgang wird von vielen Anwendern vielfach die Funktion SVERWEIS() angewendet.
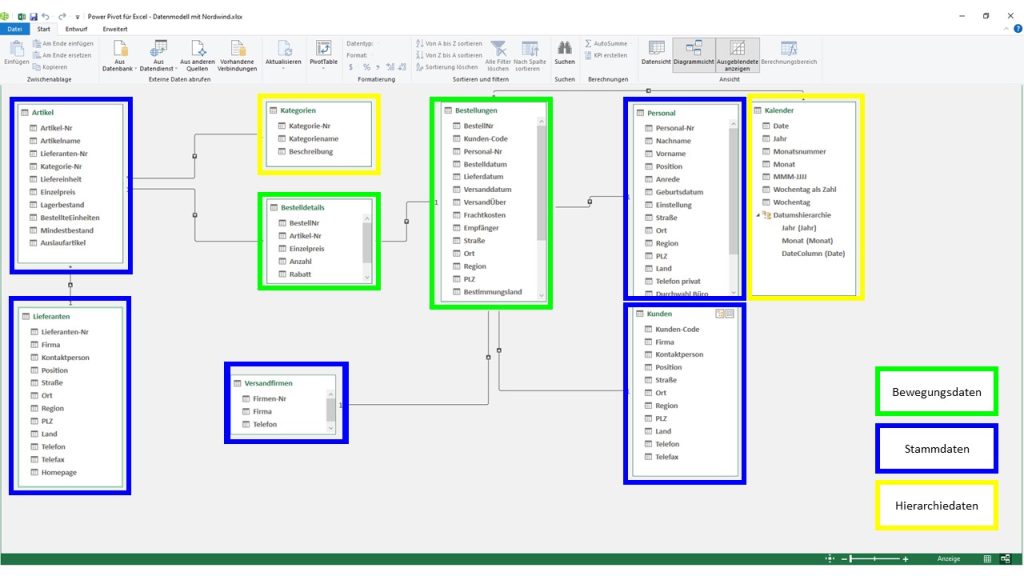
Hierarchietabellen schaffen Kategorien für die Stammdaten und erleichtern so das Zusammenfassen von Daten. Das geschieht nun im Datenmodell und ist so deutlich performanter als eine Gruppierung in der Pivot-Tabelle.
Was sind Measures?
Ein Measure ist eine Formel, die speziell für die Verwendung in einer Pivot-Tabelle (entspricht einem berechneten Feld) auf der Basis eines Power Pivot-Datenmodells (=lokaler OLAP-Cube) erstellt wird. Ein Measure wird im Wertebereich einer Pivot-Tabelle verwendet. Bei einer berechneten Spalte oder einer Pivot-Tabelle werden bei jeder Veränderung (z.B. Auswahlfilter) alle Berechnungen im sogenannten Pivot-Cache aktualisiert. Das ist bei größeren Datenmengen sehr unperformant.
Dagegen werden Berechnungsergebnisse von Measures im Datenmodell gespeichert und nur dann neu berechnet, wenn die Datenquellen durch das Datenmodell aktualisiert werden. Das bedeutet unter Umständen eine einmalige längere Aktualisierung und Berechnung der Daten versus einer permanenten, lang andauernden Aktualisierung. Measures sind daher immer performanter als berechneten Spalten im Datenmodell oder berechnete Felder in der Pivot-Tabelle. Measures werden mit DAX-Funktionen erstellt.
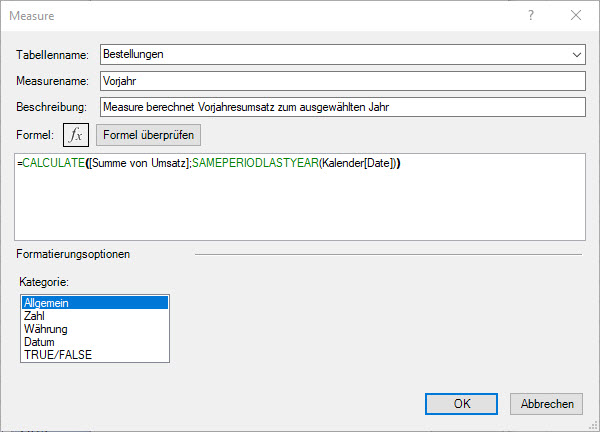
Was sind DAX-Funktionen?
DAX (Data Analysis Expressions) ist eine Analysesprache, mit der Daten aus tabellarischen Modellen abgerufen (ähnlich SQL) werden können. Dazu gibt es eine DAX-Bibliothek[1] mit Funktionen, Operatoren und Konstanten, die kombiniert werden können, um Formeln und Ausdrücke in Power Pivot für Excel zu erstellen. Auch in Power BI-Desktop können DAX-Funktionen angewendet werden. DAX-Funktionen sind den Ihnen bekannten Excel-Tabellenfunktionen sehr ähnlich und ermöglicht es Ihnen, mit Zeichenfolgen zu arbeiten, Berechnungen mit Datums- und Uhrzeitangaben durchzuführen und bedingte Werte zu erstellen. Ein großer Teil der Excel-Tabellenfunktion ist hier integriert. Trotz der Ähnlichkeit zu Excel-Tabellen-Funktionen gibt es gravierende Unterschiede in der Logik und Syntax von DAX-Funktionen und müssen daher erlernt werden. Besonders interessant sind die Funktionen der sogenannten ZeitIntelligenz, mit deren Hilfe Berechnungen möglich sind, die in Excel so nicht angeboten werden. Abbildung 4 zeigt so eine Funktion. Daneben gibt es bspw. Funktionen, die das erste oder letzte Datum eines Monats, eines Quartals oder eines Jahres im aktuellen Kontext der Berechnung zurückgeben. Oder Funktionen, die im Kontext einen kumulierten Wert für den Monat, das Quartal oder das Jahr zurückgeben.
Neben Power Pivot kommen DAX-Funktionen auch in Power BI-Desktop zur Anwendung.
Das Video zeigt die Nutzung eines Measures zur Berechnung des Vorjahresumsatzes in Kombination von Datenschnitten.
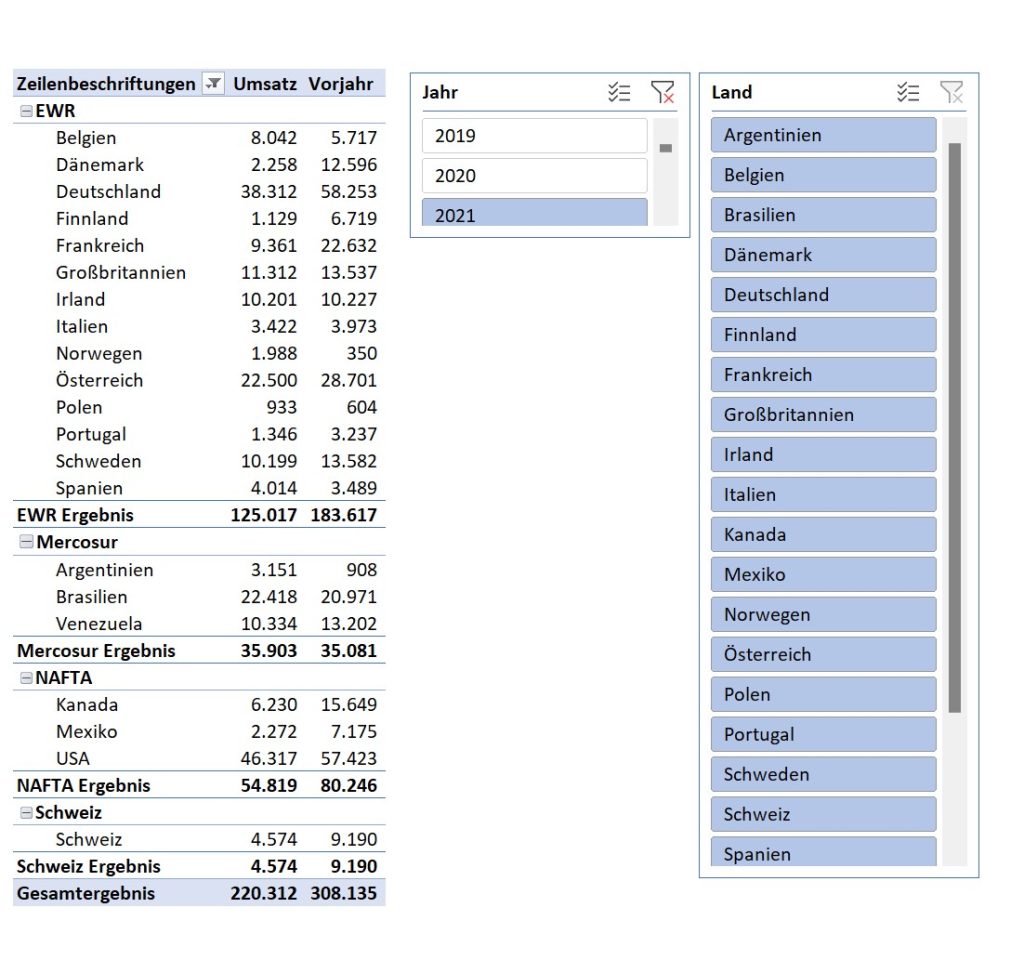
Was ist der Nutzen von Power Pivot?
Big Data ist kein genau exakt definierter Begriff, dennoch wird niemand wird auf die Idee kommen, Datenmodell im Volumen von Exabyte mit Hilfe von Excel zu erstellen. Datenmodelle mit bis zu 4GB Rohdaten und blitzschneller Datenanalyse sind kein Problem. Das Aktualisieren der Daten und das erneute Laden der Datenquelle in das Datenmodell dauert selbstverständlich einmalig Zeit, aber das sind Antwortzeiten, die OLAP-Anforderungen schon sehr nahe kommen.
Im Grunde ist Power Pivot eine Datenbank, die dem Excel-Anwender viel Vertrautes anbietet, so das keine speziellen Datenbank-Kenntnisse erforderlich sind. Mit ein wenig Anleitung kann das Datenmodell gut genutzt werden. Da in vielen Unternehmen der Einsatz von Microsoft Access nicht erwünscht ist, könnte Power Pivot eine Alternative sein, wenn eine Datenbank als Single-Source-of-Truth benötigt wird. Beispielsweise als Datenbasis für ein Reporting-System oder ein Dashboard.
In der klassischen Pivot-Tabelle ermöglicht die Gruppierungsfunktion automatische oder individuelle Aggregationen nach Datum, Intervallen oder anderen Prinzipien. Das Datenmodell von Power Pivot bietet aber die Möglichkeit, mittels „Übersetzungstabellen“ diese Gruppierungen nach weiteren Kriterien zu steuern, bspw. wenn das Geschäftsjahr vom Kalenderjahr abweicht und daher eine andere Quartalszuordnung wichtig wird.
Aber der große Vorteil von Power Pivot ist die Fähigkeit mit großen Datenmengen (> 1,5 Mio. Datensätze), bei denen Berechnungen permanent aktualisiert werden müssen, zu arbeiten. Nutzt die klassische Pivot-Tabelle dafür den sog. Pivot-Cache, setzte Power Pivot ebenfalls einen Pivot-Cache ein, nutzt aber für die Neuberechnungen das Datenmodell, also die „Datenbank“.
Der Pivot-Cache ist ein spezieller Speicherbereich, der im Hintergrund einer Excel Datei entsteht, sobald die erste Pivot-Tabelle erstellt wird. Gleichzeitig verändert sich die Dateigröße erheblich. Die Daten der Datenquelle werden dabei in diesen Cache eingelesen und die Pivot-Tabelle nutzt für ihre Analysen diesen Cache, und nicht die ursprüngliche Datenquelle.
Um diesen Nutzen zu erhalten, muss man sich allerdings Kenntnisse der DAX-Funktionen aneignen. Dafür stellt Microsoft mit Power Pivot kostenlos OLAP-Technologie zur Verfügung, die man in früheren Versionen des SQL-Servers teuer mit den Analysis-Services zukaufen musste. Es können heterogene Datenquellen wie Datenbankserver-Systeme, Excel-Dateien und Textdateien zu einem Datenmodell verbunden werden, solange keine Nachbearbeitung der Daten erforderlich ist. Dafür könnte man allerdings Power Query nutzen und das Ergebnis der Transformation an ein Power Pivot-Modell übergeben, sprichwörtlich mit einem Klick.
Das Video zeigt ein Datenmodell mit einer Ausgabe als Power Pivot-Tabelle und als Cube-Funktionen, gesteuert mit Datenschnitten.
Mit Power Pivot eingeführt und seitdem auch für die „normale“ Pivot-Tabelle verfügbar, sind die sogenannten Datenschnitte (Slicers). Das sind intuitiv bedienbare Filter für die Pivot-Tabelle! Wenn man die Power Pivot-Tabelle in CUBE-Funktionen konvertiert, wird die geschlossene Struktur der Power Pivot-Tabelle in einzelne Zellen mit CUBE Funktionen aufgelöst. Diese greifen weiterhin auf den lokalen OLAP-Cube zu, ermöglichen aber das Verteilen (Drag & Drop) der Zellen im Excel-Modell. Jede Zelle kann nun völlig frei angeordnet, ja auch auf anderen Sheets eingefügt werden, ohne dass die Verbindung zur Datenquelle gekappt wird. Die Datenschnitte steuern dann, was konkret in den Zellen an Werten angezeigt wird. Aus Sicht des Autors der schnellste Weg, um ein performantes Dashboard zu erstellen.
Was ist zu tun, um Power Pivot effizient zu nutzen?
Power Pivot lässt sich nur bedingt intuitiv selbst erlernen, wie Excel. Das hat damit etwas zu tun, dass
- Power Pivot im Grunde die Anwendung von Datenbank-Logik voraussetzt,
- die performante Anwendung von DAX-Funktionen erwartet und
- eine effiziente und effektive Datenmodellierung voraussetzt.
Mit Datenbank-Logik ist das Verständnis darum gemeint, dass alle Tabellen des Datenmodells eindeutige Spaltenüberschriften (=Header) haben und nur aus Datensätzen (=Zeilen) bestehen, die in Spalten angeordnet sind. Eventuell notwendige Berechnungen finden ausschließlich in zusätzlichen Spalten für jeden Datensatz statt und nicht in einzelnen Zellen. Es gibt keine in der Tabelle angeordneten Zwischenergebnisse, dafür gibt es die Measures und dafür benötigt man die DAX-Funktionen. Die sind ähnlich den Excel-Tabellen-Funktionen, im Detail aber doch recht unterschiedlich. Abbildung 7 zeigt den Unterschied zwischen der Funktion SUMMEWENNS(Excel-Tabellenfunktion) und der Kombination aus SUM/CALCULATE(DAX-Funktionen), die auf verschiedene Art das Gleiche berechnen.

In Abbildung 3 sind an den Linien Verbindungen zwischen den Tabellen erkennbar. Diese Verbindungen sind technisch gesehen einfach zu erstellen, allerdings ist hierbei eine Planung der Verbindungen – Datenmodellierung genannt – sinnvoll. Damit kann eine gute Performance des Modells und eine hohe Flexibilität der Auswertung gewährleistet werden. Stern-Schema oder Schneeflocken-Schema stellen je nach Aufgabenstellung Geschwindigkeit und die erforderliche Datengranularität der Daten sicher und müssen daher vorher gut überlegt sein.
Die Voraussetzung für die Nutzung von Power Pivot ist die Aktivierung des AddIns, das übrigens unter den COM-AddIns und nicht unter den Excel-AddIns zu finden ist. Dieses AddIn ist wird seit Excel 2013 mit der Office Lizenz geliefert und muss nur aktiviert werden. Für die Versionen davor kann es kostenlos von der Microsoft-Website[2] heruntergeladen werden, sofern man als Anwender Administratorenrechte für das eigene Notebook, den eigenen PC besitzt. In diesem Fall müsste dann die IT-Abteilung behilflich sein. Allerdings ist dieses AddIn nicht in jedem Unternehmen willkommen, die Gründe dafür sind dem Autor nicht bekannt und in der IT-Strategie des Unternehmens zu suchen. Es gilt dann also die IT-Administratoren vom Nutzen von Power Pivot zu überzeugen. Dann bekommen Sie – oder vielleicht das ganze Unternehmen – sicher Zugriff! Hauptargument dafür könnte eine Entlastung der IT von Business-Intelligence-Aufgaben sein.
Braucht man also Power Pivot?
Die Nutzung von Power Pivot setzt in gewisser Weise ein „Loslassen“ der gewohnten Vorgehensweise in Excel zur Datenanalyse voraus. Liegt eine überschaubare Anzahl von Datensätzen (< 1 Mio.) vor, dann sollte man eher auf eine Kombination von Power Query und einer „normalen“ Pivot-Tabelle setzen, wenn die Dynamik der Pivot-Tabelle erwünscht ist.
Ist also Power Pivot empfehlenswert? Unbedingt! Denn es ermöglicht die Analyse von Daten jenseits der Grenze von 1,5 Mio. Datensätzen mit einer guten Performance! Nicht nur die Datenanalyse ist sehr performant, auch ein Dashboards ist schnell und einfach damit erstellt. Auch hier gilt frei nach IKEA: Entdecken Sie die Möglichkeiten von Excel, aber die richtigen!
Und: Was Power Pivot übrigens nicht kann, ist Daten zu pivotieren. Dazu braucht es in Excel die Pivot-Tabelle! 😉
[1] Dokumentation von Microsoft https://docs.microsoft.com/de-de/dax/dax-function-reference, letzter Aufruf am 13.4.2022
[2] https://www.microsoft.com/de-DE/download/details.aspx?id=43348
Die Datenquellen für die gewünschten Charts werden nicht mehr über ein Pivot-Tabelle, sondern direkt aus dem Power Query-Modell heraus erzeugt. Pivot-Tabellen dienen nun ausschließlich der Datenanalyse und werden ebenfalls direkt als Verbindung aus dem Datenmodell „gefüttert“.

Eine Antwort
Danke für den tollen Artikel!
Ich bin begeistert und werde es sofort ausprobieren. Als langjähriger Access user sollte dies kein echtes Problem darstellen (hoffe ich)
Grüße
Jens