In verschieden Beiträgen dieses BLOGS und in unseren Seminar warnen wir davor, bei der Anwendung von Excel das Prinzip der Datenkonsistenz zu verletzen. In diesem Beitrag möchte ich kurz beschreiben, was Datenkonsistenz ist und bei welchen Gelegenheiten oder mit welchen Excel-Techniken man Gefahr läuft, dieses wichtige Prinzip zu verletzen. Warum ist dieses Prinzip wichtig? Wenn auf der Basis eines Excel-Modells wichtige Unternehmensentscheidungen getroffen werden, sollten sie durch einen Revisionsprozess nachvollziehbar und prüfbar sein!
In relationalen Datenbanken versteht man unter Konsistenz die Integrität von Daten, die sogenannten Integritätsbedingungen definiert wird. Kurz gesagt: Als Konsistenz kann man die Korrektheit der in Datenbanken gespeicherten Daten bezeichnen. Inkonsistente Datenbanken können zu schweren Fehlern führen, falls die mit den Daten arbeitende Software (z.B. SAP) Anwendungsschicht nicht damit solchen Fehlern „rechnet“. Nicht nur bei relationalen Datenbanken und in der Welt verteilten Systeme spricht man von Konsistenz der Daten.
Nach jeder durch eine Transaktion gegebenen Reihe von Veränderungen der Daten (Einfügen, Löschen oder Ändern) wird die Datenbank auf die Integritätsbedingungen geprüft. Wenn nur eine eine Integritätsbedingung verletzt wird, wird die Datenbank als nicht konsistent oder inkonsistent bezeichnet. In diesem Fall, muss die gesamte Transaktion so zurück abgewickelt werden, dass der vorige (konsistente) Zustand wiederhergestellt wird (Rollback).
Verletzung der Datenkonsistenz in Excel
Folgt man diesem für Datenbanken geltendem Prinzip, dann müsste man für Excel-Modelle Integritätsregeln aufstellen und dafür sorgen, dass diese nicht verletzt werden. Geschieht das dennoch, müssten die letzten Transaktionen rückgängig gemacht werden können. Das ist ohne VBA unmöglich. Nun gibt es einige bestechend einfach anzuwendende Excel-Techniken, die schnell zu einem Erfolg führen, langfristig gesehen aber eher Probleme verursachen (können). Bei folgenden Excel-Techniken sehe ich Gefahren für die Datenkonsistenz:
- Kopieren/Ausschneiden und Einfügen von Daten
Nehmen Sie an, Sie hätten aus (z.B. SAP) einen Report als Datei exportiert und kopieren oder schneiden bestimmte Daten aus diesem Report aus und fügen diese Daten in einer Excel-Datei wieder ein. Die Herkunft der Daten ist nicht mehr überprüfbar. Vor allem dann, wenn die nächste Technik angewendet wird: - Sortieren von Daten
Beim Sortieren von Daten in Datenbanken werden Datensätze sortiert. Bei falscher Markierung in Excel wird u.U. nur ein Teil der Daten sortiert. Wie auch immer, die Sortierung lässt sich Monate später nicht mehr zum Ursprungszustand zurückverfolgen. - Filtern von Daten
Beim Filtern von Daten, so schön das auch sein kann, wird ein Teil der Daten ausgeblendet. Es ist leider schon oft übersehen worden, dass es sich in diesem Zustand um gefiltert Daten handelt und die Teilmenge wurde als Gesamtheit kopiert und an dritter Stelle wieder eingefügt. Das Filtern lässt sich wieder rückgängig machen, nicht aber wenn es mit dem…. - Ausblenden von Zellen
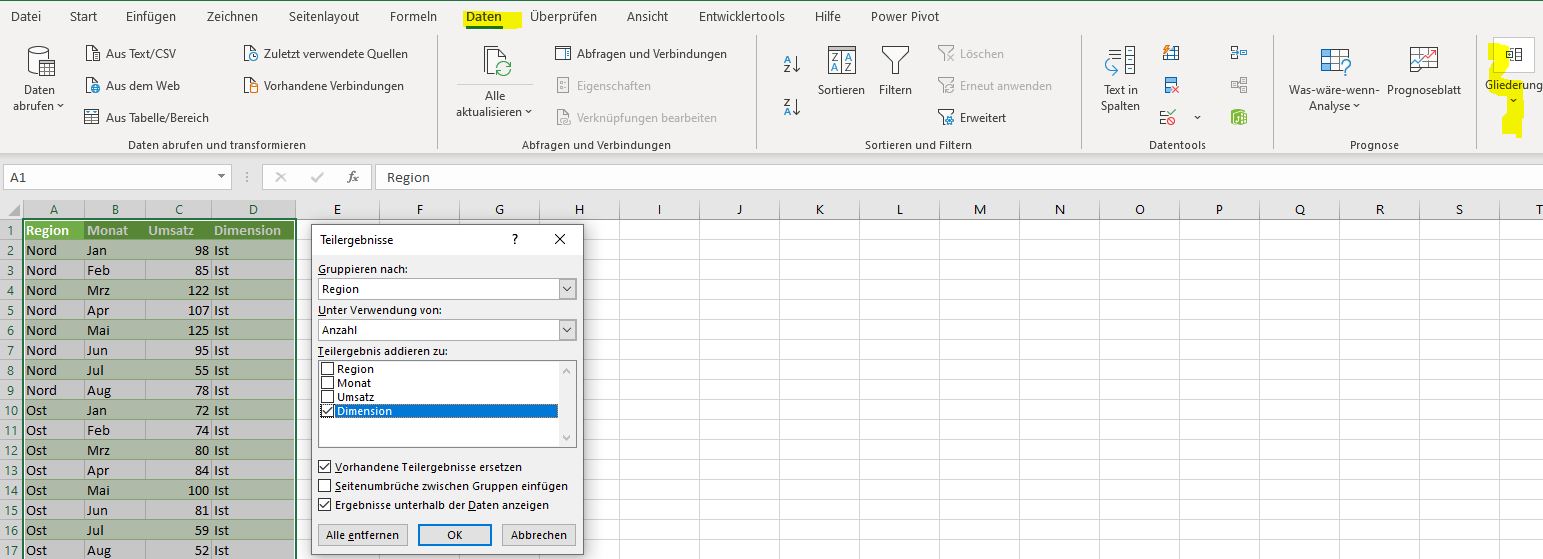
verbunden wird. Ähnlich, wie beim Filtern, kann man ausgeblendete Zellen an der blauen Schriftfarbe in den Zeilen- und Spaltenköpfen erkennen, wird aber dennoch gerne übersehen. Der „Supergau“ ist allerdings die Funktionalität - Teilergebnis
im Menü Daten ● Gliederung, die Zwischenergebniszeilen in eine Datenliste einfügt, die zuvor aber sortiert werden muss (nicht gemeint ist die Funktion TEILERGEBNIS() aus der Kategorie „Math.&Trigon.“). Diese Aufgabe erledigt man am besten mit der Pivot-Tabelle.
Am besten, man belässt die Daten so, wie man sie in das Excel-Modell übernommen hat (idealerweise mit Power Query) und startet dann von der so erzeugten „Liste“ die gewünschten Auswertungen/Verdichtungen mit der Pivot-Tabelle sowie mit geeigneten Funktion. Aber bitte nicht mit den o.a. Techniken!